
by Stefan Milne, University of Washington
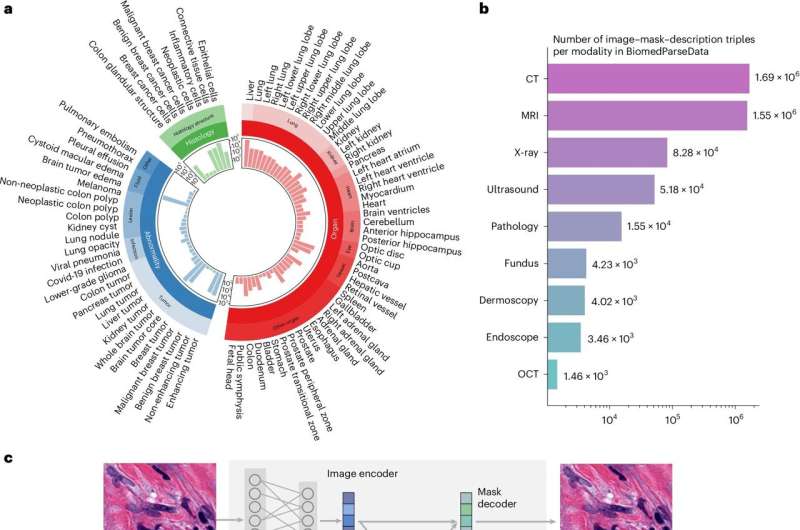
Overview of BiomedParse and BiomedParseData. Credit: Nature Methods (2024). DOI: 10.1038/s41592-024-02499-w
Artificial intelligence is making impressive strides in its ability to read medical images. In a recent test in Britain's National Health Service, an AI tool looked at the mammograms of over 10,000 women and correctly identified which patients were found to have cancer. The AI also caught 11 cases doctors had missed. But systemic diseases, such as lupus and diabetes, present a greater challenge for these systems, since diagnosis often involves many kinds of medical images, from MRIs to CT scans.
Sheng Wang, a University of Washington assistant professor in the Paul G. Allen School of Computer Science & Engineering, worked with co-authors at Microsoft Research and Providence Genetics and Genomics to create BiomedParse, an AI medical image analysis model that works across nine types of medical images to better predict systemic diseases. Medical professionals can load images into the system and ask the AI system questions in plain English.
The team published its findings Nov. 18 in Nature Methods.
UW News spoke with Wang about the tool and about the ethics and promise of AI in health care.
What does your lab study?
We're focused on multimodal generative AI, which means that we work to process multiple kinds of medical images. Previous research has considered only one type of image at a time—pathology images in cancer research, for instance. Our new approach is to consider all kinds of images together to predict systemic diseases. A disease like diabetes can show up all over the body—in the eyes, teeth, kidneys and so on. If you just have a model that can look at images of the eyes, it can miss things about systemic diseases.
You just published a paper with researchers from Microsoft and Providence Genomics that can process nine different kinds of medical images and translate between text and image. Companies like OpenAI and organizations like the Allen Institute for Artificial Intelligence have released AI models lately that can move between text and images. How are medical images different?
When ChatGPT or Google's Gemini model an image of a cat, for instance, that image is very small—let's say 256 pixels across. But medical images are much larger, maybe 100,000 pixels across. If you print both images, the difference in size is the difference between a tennis ball and a tennis court. So the same method cannot be applied to medical images.
But ChatGPT is very good at understanding and summarizing long documents. So we use the same technique here to summarize very large pathology images. We break them down into many small images, each 256 by 256. These small images form something like a "sentence" of small images, but here the basic element is not a word or character—it's a small image. Then generative AI can summarize this set of small images very accurately. In May, we announced GigaPath, a model that processes pathology images using this method.
In our latest paper, we combine tools to build BiomedParse, which works across nine modalities, allowing us to incorporate models that cover CT scans, MRIs, X-rays and so on.
We found that it's very hard to build one model that can consider all modalities because people may not be willing to share all those data. Instead, we built one model for each image type. Some are by us, some are by other experts at Harvard and Microsoft, and then we project all of them into a shared space.
We were inspired by Esperanto, a constructed language created so speakers from different countries can communicate—similar to how English functions throughout Europe now. The key idea of our BiomedParse paper is to use human language as the Esperanto for different medical imaging modalities. A CT scan is very different from an MRI, but every single medical image has a clinical report. So we project everything to the text space. Then two images will be similar not because they are both CT scans, for instance, but because they are talking about similar patients.
What are the potential applications of this tool? Would it allow general practitioners to have a better understanding of lots of different image types?
Yes, it's kind of like a search engine for medical images. It enables non-specialists to talk to the model about very specialized medical images that require domain expertise. This can enable doctors to understand images much better because, for example, reading pathology images often requires high expertise.
Even very experienced doctors can use our model to more quickly analyze images and spot subtle variations. For example, they don't need to look at every image pixel by pixel. Our model can first give some results, and then doctors can focus on those important regions. So this can make them work more efficiently, since we provide very consistent results automatically—more than 90% accuracy compared with expert human annotation—in only 0.2 seconds. Since this is a tool that detects the location of biomedical objects and counts the number of cells, 90% accuracy is often tolerable for us to correctly detect the object and predict the downstream diseases. But doctors' guidance is still necessary to ensure that these AI tools are used properly. This is a way to augment their skills, not replace them.
Will this be available to doctors?
We have already released a demo. Next, we hope to partner with UW Medicine to further develop the model and then deploy it with patients' consent in the UW Medicine system. It's a very large effort across the UW. We've collected lots of data covering different regions of the human body, different modalities and different diseases. So we hope we can advance the detection of systemic diseases.
Obviously, generative AI systems have various problems. Text models hallucinate information, returning wrong answers and making up facts. Image generators distort things. Are there concerns about applying this data to something as sensitive as medical imaging?
We actually have another paper under submission that is specifically targeting ethical problems for generative AI in medicine. One problem is hallucination. For example, you could give a chest CT image to some AI models and ask what the dental problem is. This question doesn't make any sense, because we cannot tell dental problems from CT scans, but some existing AI models will actually answer this question, and obviously it's the wrong answer.
Another problem is ethical. We can give generative AI a dental image and ask, "What's the gender and age of this patient?" That is private information. Or you could ask it to reconstruct the person's face. So we are working on detecting those unethical questions and making sure that the model will refuse to answer.
What is it about applying generative AI to medicine that makes you interested in it?
I used to do drug discovery and genomics research with AI, but I found that that's a quite limited area, because developing a drug can take 5 or 10 years, and the most time-consuming part is testing the drug—trials in mice, trials in humans, and so on. I moved to medicine because I feel that AI is very powerful for analyzing image data and images along with text.
I'm also pursuing drug repurposing. It means that, for example, a drug used to treat retinal disease could, without being designed for other purposes, also treat heart failure. So if this drug is already being used for retinal disease and we find it's effective for heart failure, we can immediately apply it, because we know that it's safe. This is one of the potential benefits of studying systemic diseases with AI. If we find in combining retinal images with heart failure images that retinal images can predict heart failure, we might uncover such a drug. That's a long-term goal here.
More information: Theodore Zhao et al, A foundation model for joint segmentation, detection and recognition of biomedical objects across nine modalities, Nature Methods (2024). DOI: 10.1038/s41592-024-02499-w
Journal information: Nature Methods
Provided by University of Washington








Post comments