
by University of Texas at Austin
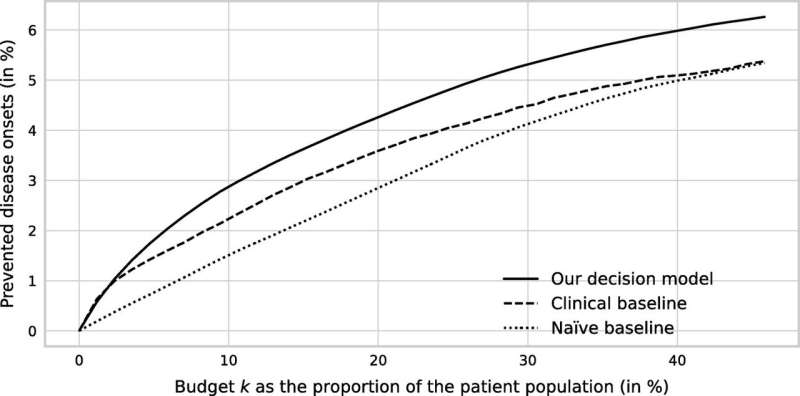
Prevented Onsets When Providing Preventive Care Under Different Budget Constraints. Credit: Manufacturing & Service Operations Management (2023). DOI: 10.1287/msom.2021.0251
Better prevention of type 2 diabetes could save both lives and money. The U.S. spends over $730 billion a year—nearly a third of all health care spending—on treating preventable diseases like diabetes.
For the 98 million adults who are prediabetic and at risk of developing type 2 diabetes, preventive treatments such as the drug metformin can help stave off the disease. But the medicines are expensive. With limited budgets, insurers and health care facilities need to allocate them to the patients they can help the most.
Currently, a health provider calculates a patient's risk of developing diabetes using a simple charting tool. Patients whose risk scores exceed a predetermined threshold get enrolled in preventive care.
Now, a new study from Texas McCombs has developed a novel tool for identifying those patients, based on artificial intelligence.
Maytal Saar-Tsechansky, a professor of information, risk, and operations management, developed an AI- and machine learning-driven model to predict which patients are most likely to benefit from preventive treatment.
"Escalating health care costs necessitate more efficient and cost-effective approaches to disease prevention, particularly preventable diseases such as type 2 diabetes," Saar-Tsechansky says.
One hurdle for allocation models is that they're often based on crude estimates of how a patient will benefit, she says. With Mathias Kraus of Friedrich-Alexander-Universität and Stefan Feuerriegel of the Munich School of Management, she leveraged a rich source of data to produce better assessments: electronic health records on 89,191 prediabetic patients from 2003 to 2012.
The records came from a health insurer that wanted to improve care for patients at risk of developing type 2 diabetes.
When the researchers applied their decision model to the insurer's data—including body measurements, lab tests, disease codes, drug prescriptions, and sociodemographic information—it improved both health and economic efficiency.
It prevented 25% more cases of type 2 diabetes from developing than the use of traditional diabetes risk scores did.
It saved $2.9 million more per 10,000 patients than savings garnered through the traditional clinical baseline method.
If applied to the entire U.S. population, the model could save $1.1 billion annually in health care costs.
"By enabling data-driven and cost-effective allocation of resources, this approach is instrumental in making preventive care more impactful," Saar-Tsechansky says.
The data-driven decision model could help prevent other conditions, she adds, such as respiratory diseases and cardiovascular disease, the leading cause of death in the U.S. It could improve patient outcomes for both, reducing long-term costs for the U.S. health care system.
Using quality data, such as accurate electronic medical health records, could lead to another benefit: more customized approaches to health care.
"For patients, especially those at risk for diseases such as type 2 diabetes, our model means a more personalized and effective approach to preventive care," Saar-Tsechansky says.
"It suggests future preventive care could be more tailored to individual risk factors, increasing the effectiveness of interventions and potentially reducing the likelihood of disease onset."
The study is published in the journal Manufacturing & Service Operations Management.
More information: Mathias Kraus et al, Data-Driven Allocation of Preventive Care with Application to Diabetes Mellitus Type II, Manufacturing & Service Operations Management (2023). DOI: 10.1287/msom.2021.0251
Provided by University of Texas at Austin





Post comments