
by Beth Duff-Brown,Stanford University
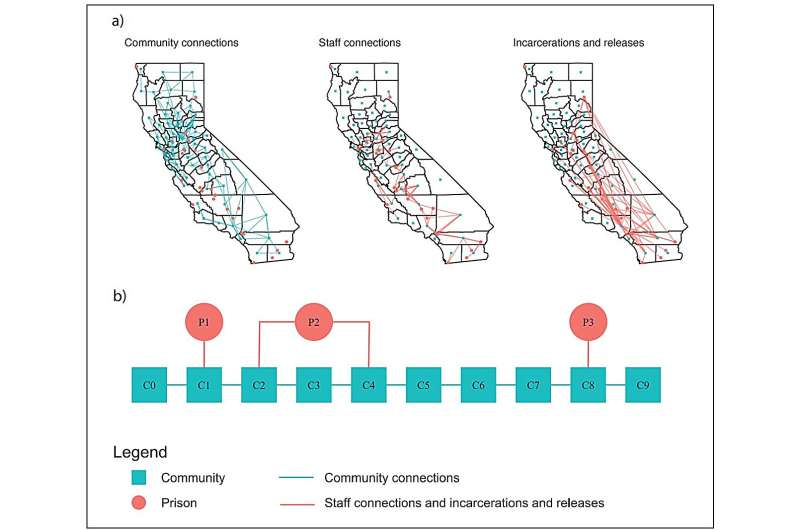
Network structures. (a) Network structure of the California network. (b) Network structure of the illustrative network. Credit:Medical Decision Making(2025). DOI: 10.1177/0272989x251378472
Stanford Health Policy researchers built a model to test whether AI could effectively manage disease spread between prisons and surrounding communities. The results were decisive.
Infectious diseases can rampage through correctional facilities at alarming rates, with outbreaks cycling in and out of surrounding communities and potentially spreading further to more distant communities.
Despite these connections, communities and prisons rarely coordinate their efforts to control outbreaks. So, Stanford Health Policy researchers conducted a study examining different ways to better protect both populations.
The researchers built a computer model to simulate how an infectious disease spreads between communities and correctional facilities. They tested several ways to control the spread of disease, including standard rules-based control policies and newer, AI-based policies developed usingreinforcement learning(RL)—a form of artificial intelligence that learns through trial and error.
The RL method used a "reward system" that balanced two goals: preventing infections and minimizing the costs of control measures.
The researchers found that the AI-based RL control policy performed significantly better than traditional approaches like those used during the COVID-19 pandemic.
They then analyzed how the best-performing control policy worked and how reliable it was under different conditions. They found that it tailored its response to the unique conditions of communities and prisons and showed patterns that helped reduce disease spread between the two. For example, as the disease spread through the network, the RL control policy focused resources on testing in communities and prisons under threat of outbreak—but before outbreaks occurred, so that early detection would allow more time to deploy additional interventions.
"Reinforcement learning is a promising method for finding efficient policies for controlling epidemic spread on networks of communities and correctional facilities, providing insights that can help guide policy," said Christopher Weyant, Ph.D., a recent SHP postdoctoral research fellow and lead author of thestudypublished inMedical Decision Making.
"Correctional facilities, such as prisons and jails, have historically had substantially higher incidence rates of respiratoryinfectious diseasesas compared to surrounding communities," said Jeremy Goldhaber-Fiebert, Ph.D., professor of health policy and the study's senior author.
He noted that during the early phases of the pandemic, prisoners in the United States had a COVID-19 incidence rate more than five times higher than the general population—a pattern also seen with other respiratory diseases like tuberculosis and influenza, and in other regions such as South America.
"Small community outbreaks can cause larger outbreaks in correctional facilities, which can in turn exacerbate the community outbreaks," Goldhaber-Fiebert said. "Despite this interdependence, epidemic control efforts in communities and correctional facilities are generally not closely coordinated."
The researchers built a simulation model of an epidemic spreading across networks of communities and correctional facilities. Using both a large California-based network and a smaller illustrative one, they compared the performance of various control strategies—including heuristic and RL approaches.
The RL strategy performed far better than the other approaches in the California network. The team compared several approaches, such as applying control measures like testing and non-pharmaceutical interventions—like masking and social distancing—to all facilities, to none, or using either a simple rules-based method or an RL strategy.
They found that the RL policy could achieve reductions in infections close to that of a "control all" approach, but with far fewer resources used for testing and much less intense non-pharmaceutical interventions.
Disaggregating benefits and costs provides guidance to policymakers considering resource allocations between communities and prisons in future epidemics. Similar results were observed with the illustrative network.
While the authors used the recent and salient example of control policies for the COVID-19 pandemic, their sensitivity analyses as well as theirprior workdemonstrate that the approach and methods they developed have value for control of a range of respiratory pathogens that could cause future pandemics.
"Our work highlights how control of an epidemic on a network of communities andcorrectional facilitiescan be robustly improved through the use of modern quantitative methods, such as RL," the team wrote. "Policymakers should consider investing in the further development of such methods and using them for future epidemics."
More information: Christopher Weyant et al, Reinforcement Learning-Based Control of Epidemics on Networks of Communities and Correctional Facilities, Medical Decision Making (2025). DOI: 10.1177/0272989x251378472
Provided by Stanford University




Post comments