
Today, we introduce an original research result entitled ‘ChemSweet: An AI-driven computational platform for next-gen ChemSweet: An AI-driven computational platform for next-gen sweetener discovery’, which aims to accelerate the screening and discovery of healthy and safe sweeteners through artificial intelligence. The corresponding author is Associate Professor Dong Jie of Xiangya School of Pharmacy, Central South University, and Master's students Qian Jie, Wang Xuejie and Song Fangliang are the co-first authors of the paper.
Research Background
With the growing demand for sweetness and the advancement of science and technology, the research on sweeteners has received increasing attention in recent years, especially on how to find safe, healthy, and low-calorie sweeteners to replace sugar and avoid sugar-induced obesity and metabolic diseases. Incidental discovery from synthetic compounds or natural products and structural modification based on conformational relationships to reproduce and amplify sweetness are the main means by which novel sweeteners have traditionally been developed. However, these approaches often rely on continuous iterative testing, which is inefficient and fails to explore sufficient chemical space. Moreover, many of the discovered molecules fail to meet the safety and stability criteria necessary for food and drug use, resulting in a significant waste of resources and time. In recent years, rapid advances in cheminformatics and food informatics have provided useful tools and databases for taste prediction and computer simulation of taste perception. Compared to traditional methods, machine learning prediction models can accelerate the development of sweeteners by quickly identifying compounds that are associated with sweet/unsweet and bitter/non-bitter and predicting their relative sweetness compared to sucrose. However, existing machine learning models still have limitations in providing a comprehensive analysis of physicochemical properties and stability, and although it is possible to predict sweetness, it is difficult to predict the safety and stability of sweeteners in complex food systems, specialised processing techniques, and during storage and transport. Therefore, there is an urgent need for a new methodology capable of predicting various key properties at an early stage of sweetener development to meet increasingly stringent toxicological safety standards, in order to reduce the high costs and lengthy timescales associated with the innovation of new sweeteners.
Results in brief
In the context of the current overconsumption of artificial sweeteners and increasing health risks, this study targeted the development of an artificial intelligence-based platform for the rapid screening of sweeteners, ChemSweet (http://chemsweet.ddai.tech). The platform builds machine-learning predictive models of ten key properties useful for developing new varieties of sweeteners, including four important physicochemical properties (water solubility, melting point, boiling point, and thermal stability), two sweetness properties (sweetness and relative sweetness), and four safety indicators (NOAEL, LD50, Ames, and BCF). By integrating these models, ChemSweet is able to perform a full-cycle, multi-dimensional assessment of candidate sweeteners and predict the biosafety and stability of candidate molecules during processing. To validate the platform's utility, the research team successfully identified 294 potential sweet molecules from the SuperNatural database that simultaneously meet multiple expected criteria.ChemSweet will become a powerful tool for identifying safe and healthy sweeteners, saving time and cost in candidate molecule screening and development, and accelerating the discovery of safe and healthy sweeteners.
Research Highlights
1. A novel artificial intelligence-based platform for rapid discovery of sweetness molecules is established. 2. A new perspective of considering sweetness and biosafety of sweeteners simultaneously is proposed. 3. Fifteen models are used to evaluate sweetness, safety and physicochemical properties. 4. The combination of 15 models is suitable for different application scenarios. 5. The validity and usefulness of ChemSweet is verified by screening a large database.
Graphical Appreciation
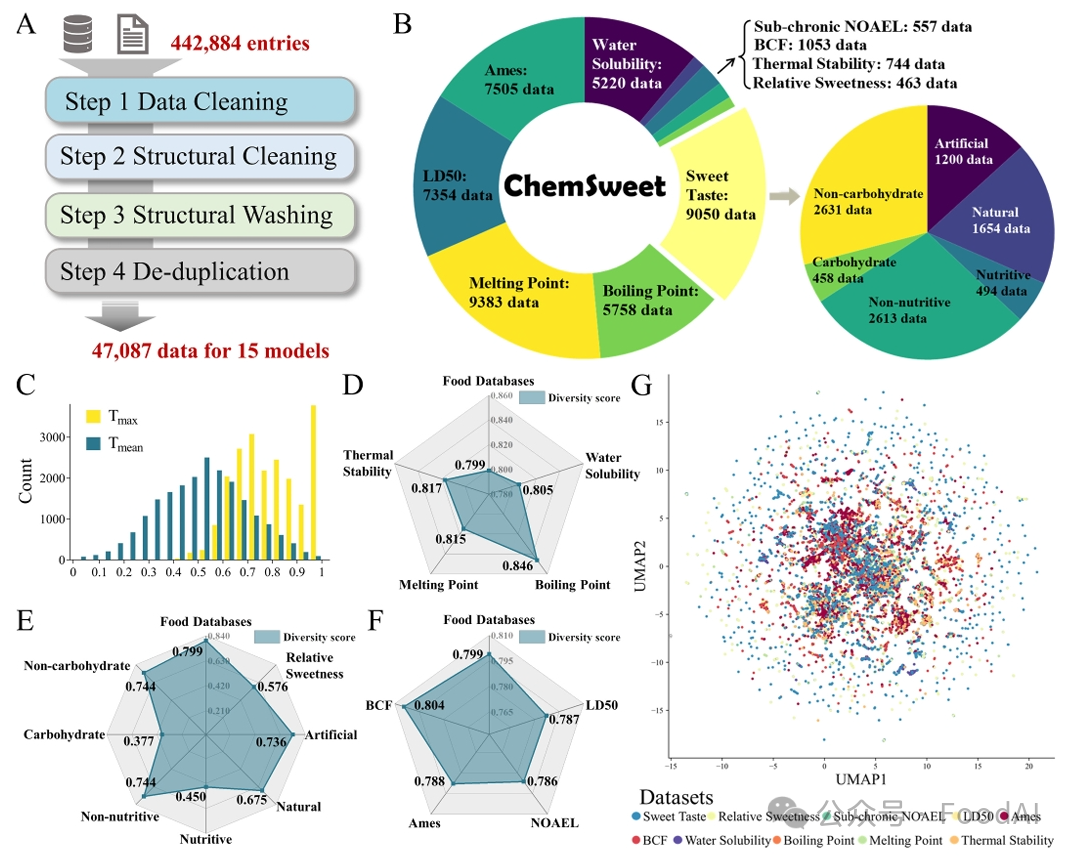
Figure 1. Overview of the ChemSweet dataset and chemical spatial analyses. (A-B) ChemSweet data collation process (A) and dataset composition (B). (C) Distribution of molecular structure similarity based on Tanimoto coefficients between ChemSweet dataset and food database. (D-F) Molecular diversity scores for the food database and ChemSweet physicochemical properties (D), sweetness (E) and safety (F) datasets. (G) UMAP projection of the ChemSweet dataset chemical space using the MOE 2D descriptor.
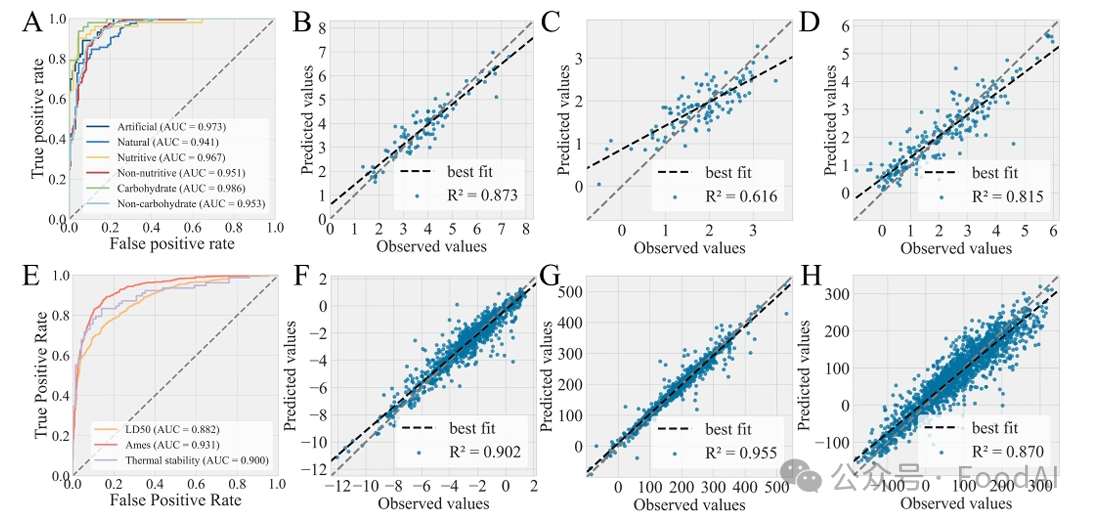
Figure 2. performance of the best models deployed in ChemSweet. ROC curves for six sweetness classification models (A) and LD50, Ames and thermal stability models (E). Prediction error plots for the relative sweetness (B), NOAEL (C), BCF (D), water solubility (F), boiling point (G) and melting point (H) models.
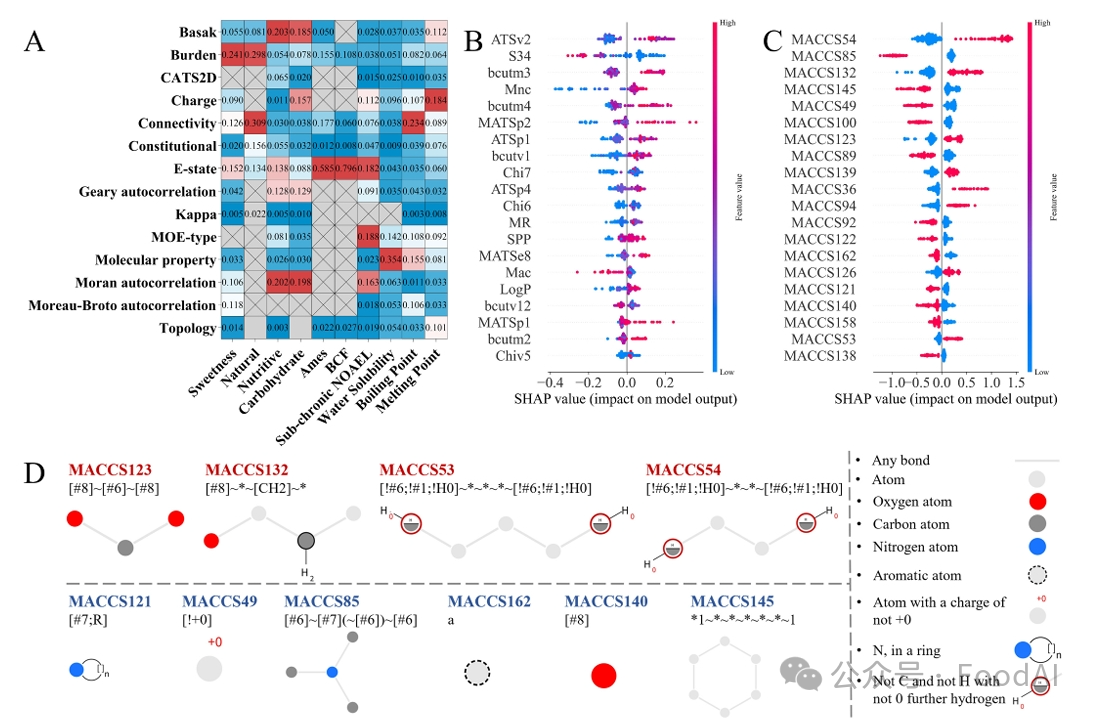
Figure 3. Model interpretation based on SHAP analysis. (A) Heat map of feature importance in the prediction model based on Shapley values for different molecular descriptor classes. (B) SHAP plot of relative sweetness prediction model. (C) SHAP plot of the sweetness classification model for artificial sweeteners. (D) The ten most important MACCS fingerprint keys jointly identified by the sweetness classification models for artificial sweeteners, non-nutritive sweeteners and non-carbohydrate sweeteners.
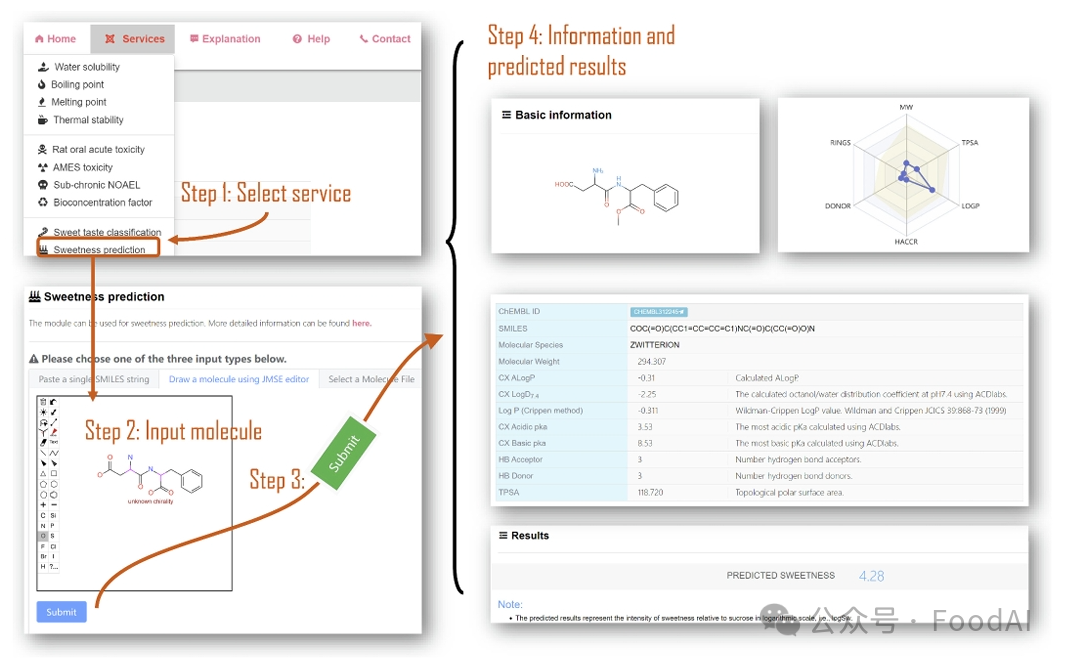
Figure 4. Screenshot of usage with the ChemSweet platform.
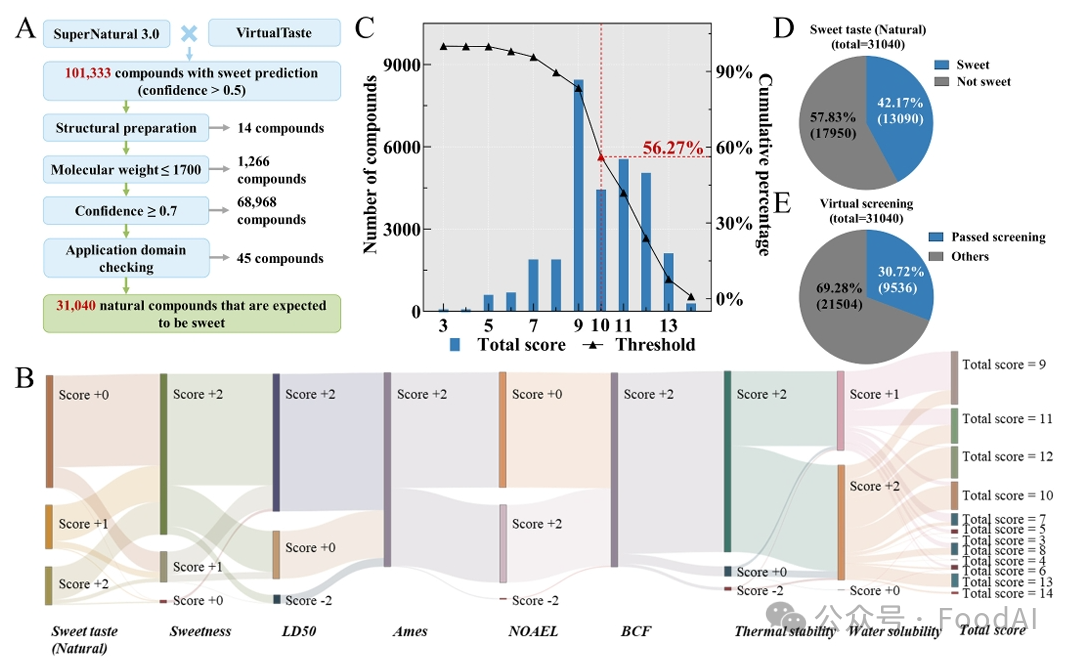
Figure 5. Virtual screening of natural product databases using ChemSweet. (A) Flowchart of data processing. (B) Sankey diagram of compounds predicted by the ChemSweet model and the total score calculated according to the scoring rules. (C) Distribution of total scores (blue bars) and percentage of compounds passing different screening thresholds (broken line with triangles). (D) Distribution of predicted results from the sweetness classification model for natural sweeteners. (E) Distribution of results after the ChemSweet virtual screening process for the natural sweetener development scenario. ‘Passed screening’ indicates sweet compounds that were identified by the natural sweetener sweetness classification model and had a total score of ≥10.
Conclusion
In this study, we proposed a new sweetener screening method and successfully constructed ChemSweet, the first multi-level virtual screening platform for sweeteners, which is a natural sweetener analysis platform based on artificial intelligence and cheminformatics, covering ten important physicochemical, sweetness, and safety indexes in the development process of sweeteners, and the constructed AI model achieved excellent performances in the test set. Excellent performance. Unlike existing tools that are limited to a single flavour profile, ChemSweet can rapidly assess multiple key properties early in the sweetener development process, not only for sweetness, but also for the safety and stability of a specific sweetener class.ChemSweet can accelerate the development process of sweet molecules for the food and pharmaceutical industries by helping to identify superior sweet molecular backbones for the development of healthier, safer, and higher-quality sweeteners. sweetening molecules in the food and pharmaceutical industries.






Post comments