
Large language models (LLMs) have captured attention due to their human-like reasoning, tool usage, and problem-solving capabilities. Moreover, their deep understanding in specialized fields such as chemistry and biology further enhances their application value. This article discusses the significant potential of LLMs in understanding disease mechanisms, drug discovery, and clinical trials—three fundamental stages of drug development.
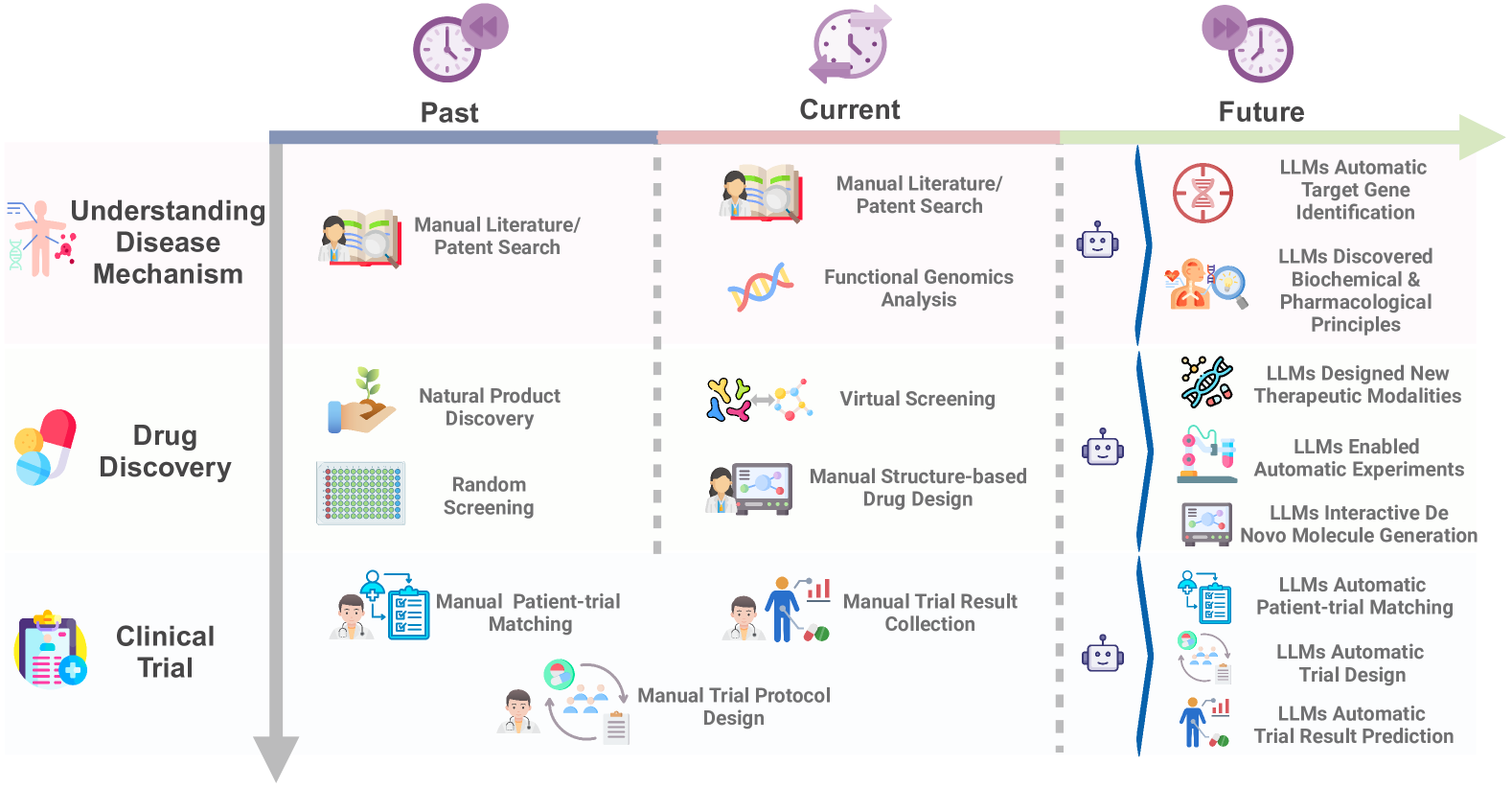
Figure 1:Large Language Models Shaping the Future Landscape of Drug Discovery and Development.
Initially, this paper reviews the past and present processes of drug research and clinical trials, highlighting the future potential applications of LLMs at these stages.
Understanding Disease Mechanisms
Past: Relied on manual literature and patent searches.
Present: In addition to manual searches, functional genomics analysis is now included.
Future: LLMs will automatically identify target genes and discover biochemical and pharmacological principles.
Drug Discovery
Past: Drug development was conducted through the discovery of natural products and random screening.
Present: Uses virtual screening and structure-based manual drug design.
Future: LLMs will design novel therapeutic approaches, automatically generate drug designs, and perform experiments autonomously.
Clinical Trials
Past and Present: Manually matching patients with trials, designing clinical trials, and collecting clinical trial data.
Future: LLMs will automate patient matching, trial design, and predict trial outcomes.
Classification of large language models
This article categorizes large language models into two types: Scientific Language Models and General Language Models. Their comparison and differences are as follows:
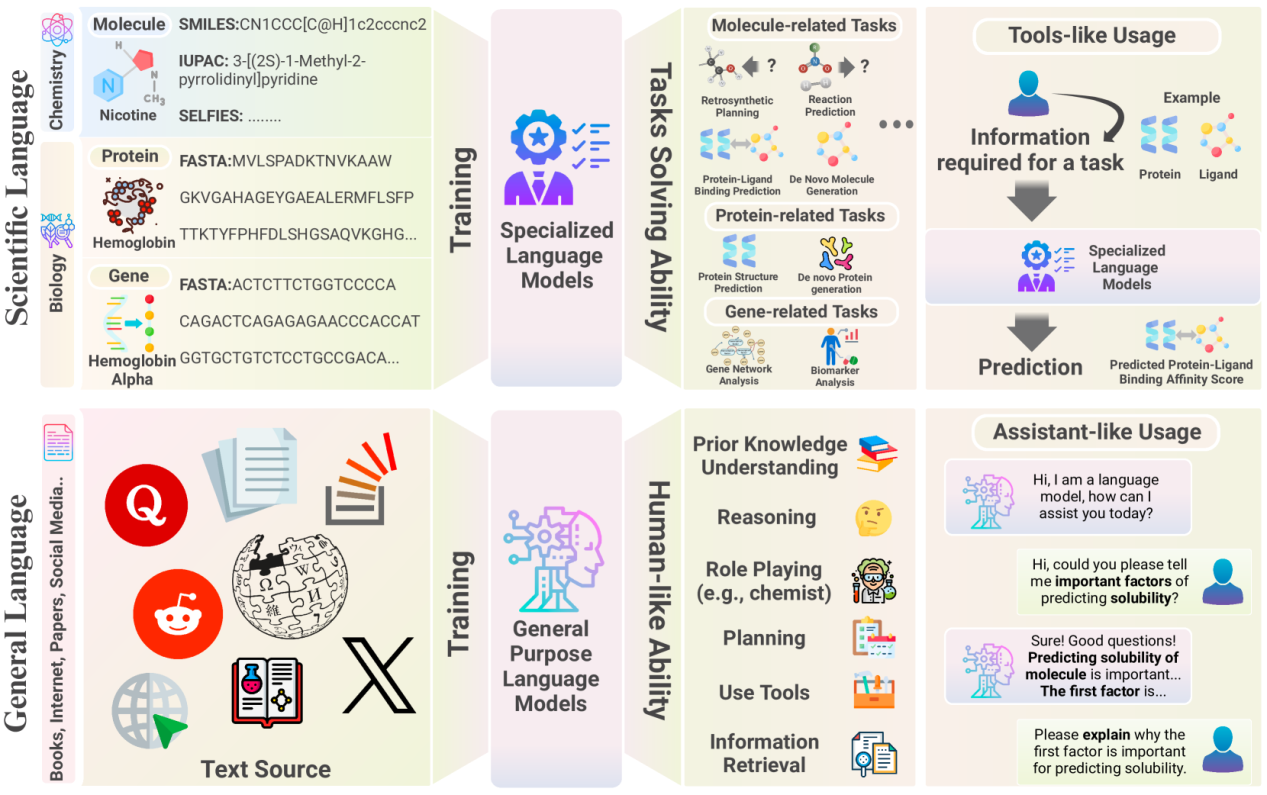
Figure 2: The two main paradigms of language models.
Scientific Language Models
Domain: Specialized areas such as chemistry (molecules) and biology (proteins, genes).
Training Data: Includes chemical SMILES, IUPAC sequences, protein FASTA sequences, and gene FASTA sequences.
Task Capability: Capable of handling tasks related to molecules, proteins, and genes, such as retrosynthetic planning, reaction prediction, molecular design, protein structure prediction, and gene network analysis.
Tool Usage: Serves as a tool by retrieving necessary information for tasks and generating predictions (e.g., protein-ligand binding affinity scores).
General Language Models
Domain: Based on broader textual data such as books, the internet, social media, etc.
Training Data: Includes books, Q&A websites, social media, encyclopedias, etc.
Human-like Abilities: Possesses understanding of background knowledge, reasoning, role-playing (e.g., as a chemist), planning, tool usage, and information retrieval.
Assistant Usage: Functions as an assistant, interacting with users, answering questions, explaining complex concepts, and helping complete tasks.
The Role of Large Language Models in Understanding Disease Mechanisms
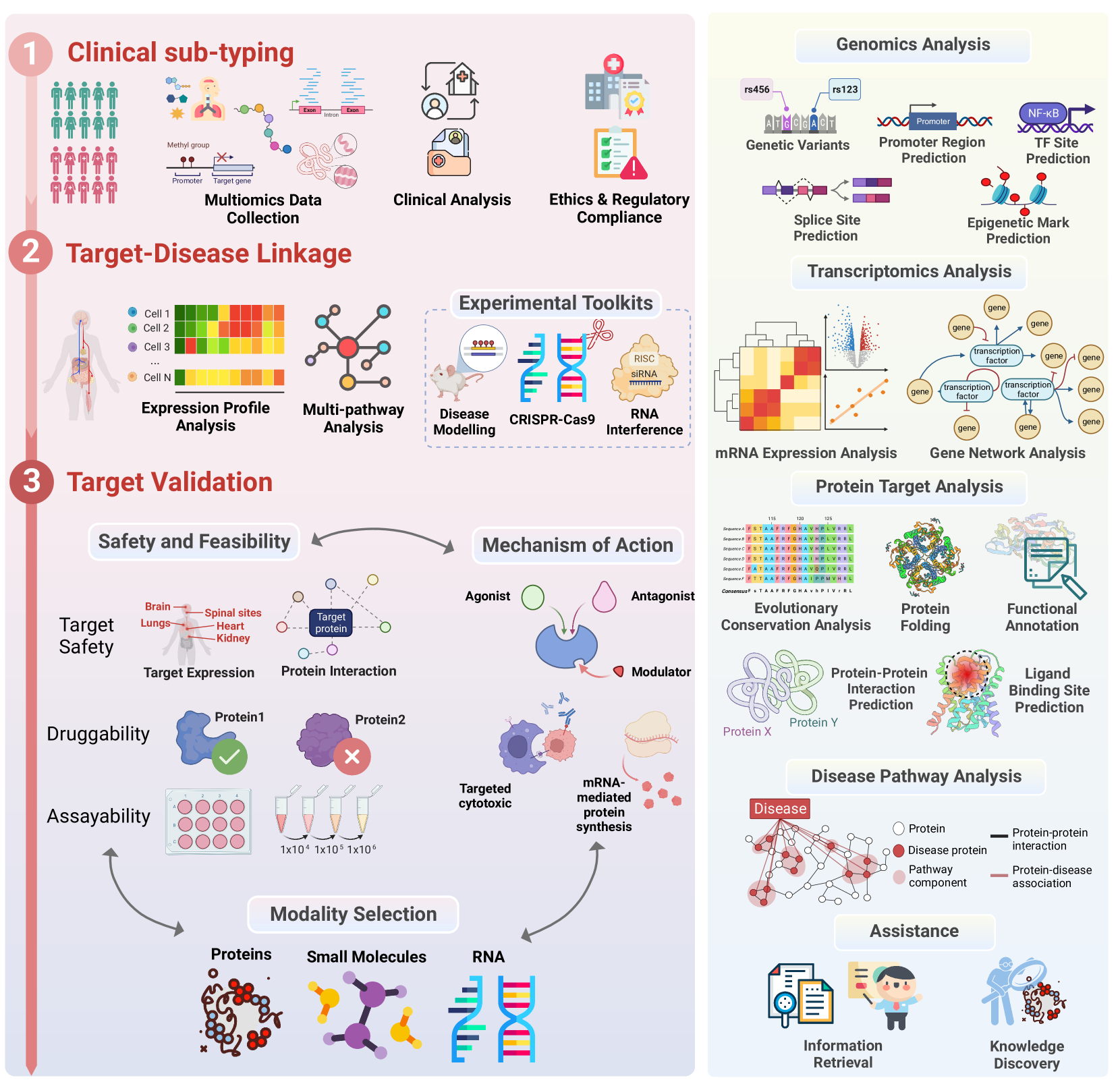
Figure 3:Understanding Disease Mechanisms.
This chart is divided into two sections: the left side shows the key processes in disease research, while the right side highlights the specific application areas of large language models (LLMs) in these processes.
Left Side: Disease Research Processes
Clinical Sub-typing: Involves collecting multi-omics data (such as genomics, proteomics, metabolomics, etc.) combined with clinical analysis and ethical regulations to classify diseases. The goal is to better understand the heterogeneity of diseases, laying the groundwork for subsequent target discovery.
Target-Disease Linkage: Uses gene expression profiling, multi-pathway analysis, and experimental tools (like CRISPR-Cas9, RNA interference, etc.) to identify and validate the association between diseases and potential therapeutic targets. This step is crucial for drug development.
Target Validation: Verifies the safety and feasibility of the target and evaluates its drug development potential. This includes assessing target safety, druggability, and testing feasibility. The mechanism of the target (e.g., agonists, antagonists, modulators) is confirmed in this stage to choose appropriate treatment approaches, such as proteins, small molecules, or RNA therapies.
Right Side: LLM Application Areas
Genomics Analysis: LLMs can assist in predicting gene variants, promoter regions, transcription factor binding sites, and other information, helping researchers understand disease mechanisms at the genomic level.
Transcriptomics Analysis: LLMs can handle complex data like mRNA expression analysis and gene network analysis, assisting researchers in extracting important transcriptomic information to understand gene regulation patterns and expression differences.
Protein Target Analysis: LLMs can predict protein structure, functional annotations, protein-protein interactions, and ligand binding sites, helping researchers identify potential drug targets.
Disease Pathway Analysis: LLMs can analyze the complex interactions between proteins and diseases in disease pathway analysis, identifying potential therapeutic targets and intervention pathways, thus accelerating the drug development process.
Assistance: LLMs also provide auxiliary functions such as knowledge discovery and information retrieval, enabling researchers to quickly access relevant information and expedite the research process.
Application of Large Language Models in Drug Discovery
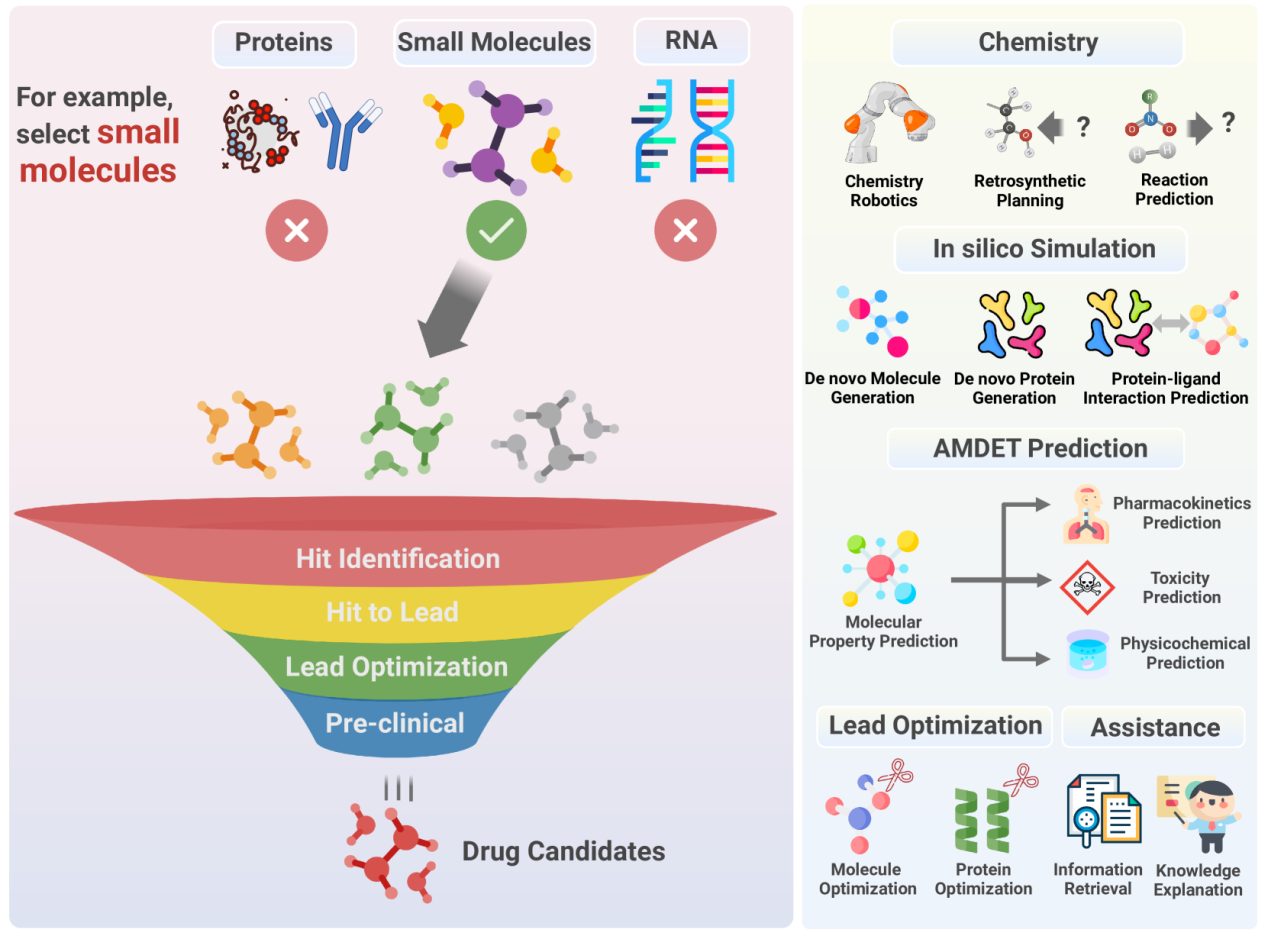
Figure 4:Drug Discovery.
This chart is divided into two sections: the left side outlines the drug discovery process, while the right side illustrates the specific applications of large language models (LLMs) in each stage of drug discovery.
Left Side: Drug Discovery Process
Drug Type Selection:
Scientists can choose from various therapeutic approaches, including proteins, small molecules, and RNA. This chart uses small molecules as an example to demonstrate their application in drug development.
Drug Discovery Workflow:
Hit Identification: Involves screening a large number of compounds to identify molecules that show initial activity against a target.
Hit to Lead: Further optimization of these initial hits to improve their binding affinity with the target.
Lead Optimization: Structural modifications of lead compounds to enhance their efficacy and drug-like properties.
Pre-clinical: Evaluates the safety and efficacy of candidate drugs before they enter clinical trials.
Drug Candidates: The final stage where potential candidates are produced and prepared for clinical trials.
Right Side: LLM Application Areas
Chemistry: LLMs can assist with tasks such as automated chemical synthesis, retrosynthesis planning, and reaction prediction through chemical robotics, helping chemists accelerate compound discovery.
In Silico Simulation: LLMs can generate molecules, proteins, and predict protein-ligand interactions, speeding up the virtual drug screening process.
ADMET Prediction: LLMs can predict the pharmacokinetics, toxicity, and physicochemical properties of drug candidates, aiding in the evaluation of how drugs behave in the human body.
Lead Optimization: LLMs can optimize molecular structures and protein interactions, improving the efficacy and safety of lead compounds.
Assistance: LLMs also provide functions such as information retrieval and knowledge interpretation, enabling researchers to quickly access the necessary information and enhance drug development efficiency.
Applications of Large Language Models in Clinical Trials
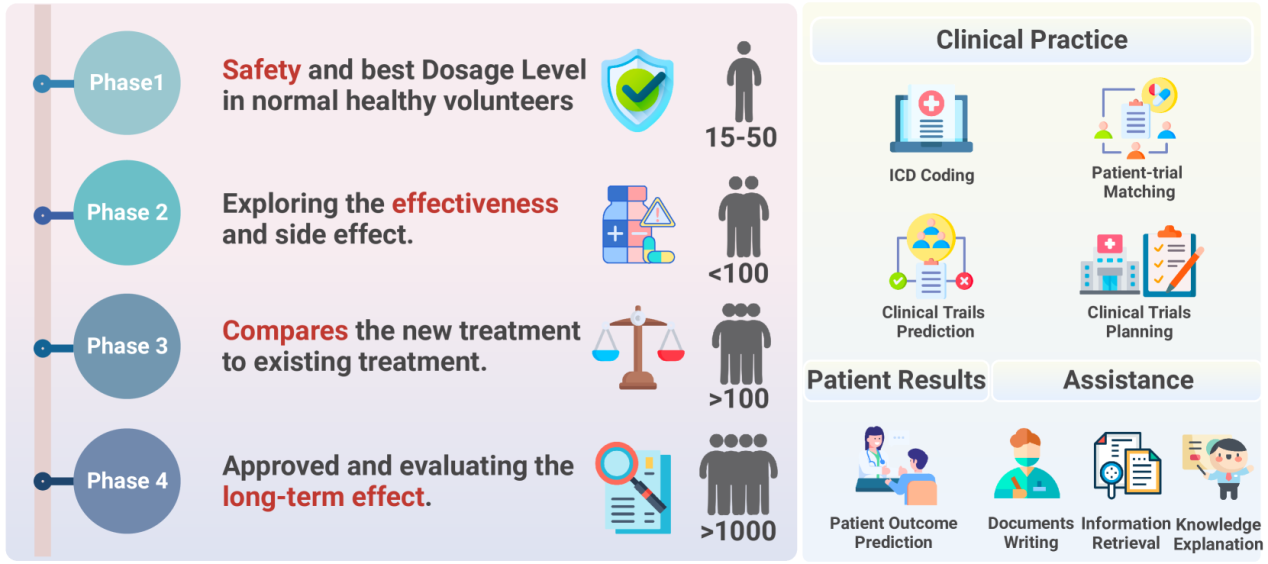
Figure 5:Clinical Trials
This chart presents the different stages of clinical trials on the left and the applications of large language models (LLMs) in these stages on the right.
Left Side: Clinical Trial Stages
Phase 1: Primarily tests the safety and optimal dosage levels of the drug. Usually conducted with 15 to 50 healthy volunteers.
Phase 2: Explores the drug’s efficacy and potential side effects, typically involving fewer than 100 participants.
Phase 3: Compares the new treatment with existing treatments to verify the effectiveness of the new drug, generally involving more than 100 participants.
Phase 4: After the drug is approved, assesses its long-term effects, often with over 1,000 participants.
Right Side: LLM Application Areas
Clinical Practice:
ICD Coding: Assists in generating and optimizing disease classification codes.
Patient-Trial Matching: Automatically matches suitable clinical trials by analyzing patient characteristics.
Clinical Trial Prediction: Predicts the success rates and outcomes of clinical trials.
Clinical Trial Planning: Helps researchers develop effective clinical trial plans.
Patient Results:
Patient Outcome Prediction: Predicts patient treatment outcomes based on existing data.
Assistance:
Document Writing: Helps generate clinical trial-related documents and reports.
Information Retrieval: Quickly searches for and organizes relevant trial information.
Knowledge Interpretation: Interprets complex medical or pharmaceutical information, making it easier for researchers and physicians to understand.
Maturity Assessment of Large Language Models in Drug Development
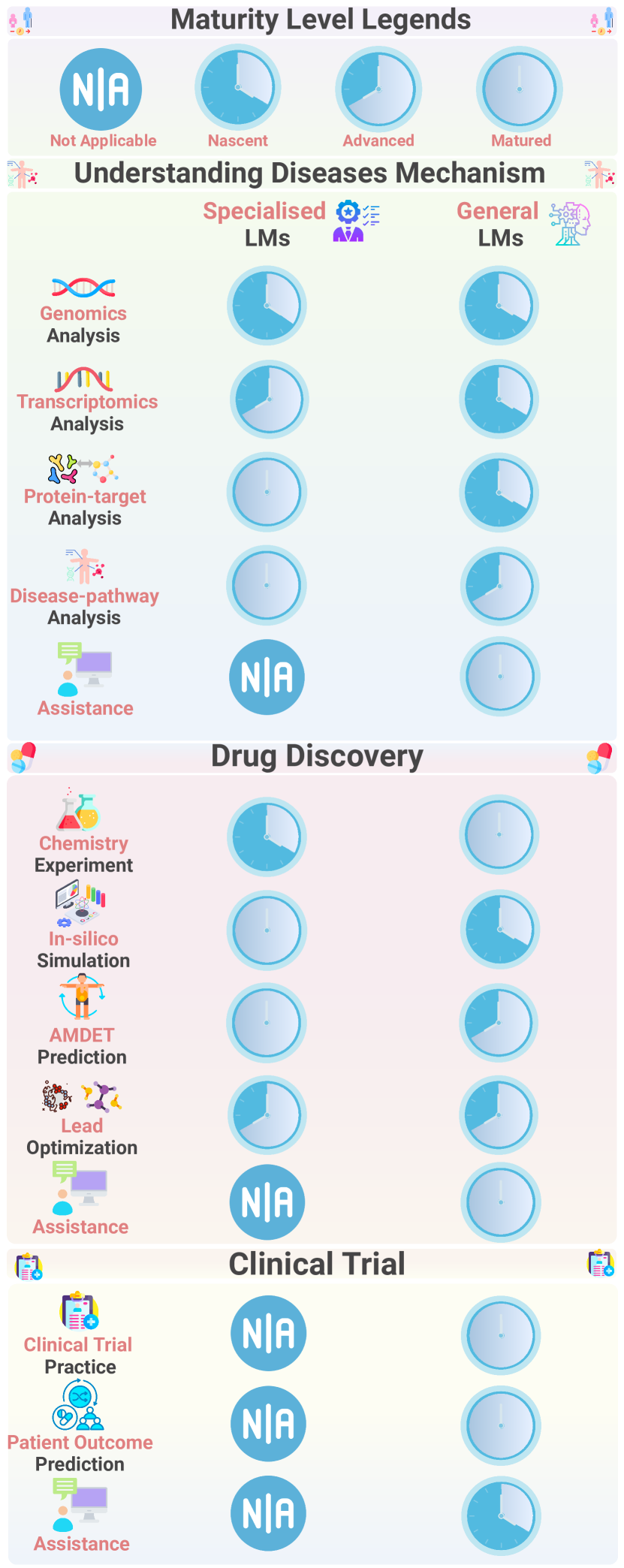
Figure 6:Maturity Assessment of LLMs in Downstream Tasks.
This chart presents the maturity levels of two types of large language models (LLMs): Specialized LMs and General LMs, across their applications in understanding disease mechanisms, drug discovery, and clinical trials. The application maturity is divided into four levels: nascent, advanced, matured, and not applicable (N/A):
Not Applicable (N/A): This type of LLM is not suitable or relevant for the given downstream tasks. In these cases, the LLM paradigm is not considered an effective or applicable tool.
Nascent: The LLM paradigm has been initially applied to tasks, often in in silico (computer simulation) environments, but lacks support from real-world experimental validation. Applications in this phase are more theoretical or exploratory and have not been tested in real-world scenarios.
Advanced: LLM applications have gone beyond theory and have been experimentally validated in real-world scenarios. These experiments show that LLMs can serve specific tasks in practice, but they may not be widely deployed yet.
Matured: LLM applications have been integrated into real-world working environments, such as hospitals or pharmaceutical companies, with clear evidence of their effectiveness and practicality. At this stage, LLMs are widely used and have yielded significant practical results.
Understanding Disease Mechanisms
Genomics Analysis and Transcriptomics Analysis: These areas are primarily still in the nascent stage, meaning that they are largely in the exploratory phase with limited real-world validation.
Protein-target Analysis and Disease-pathway Analysis: These areas are more matured, as LLMs have shown practical value and are being effectively applied in real-world drug development environments.
Drug Discovery
Chemistry Experiment, In-silico Simulation, ADMET Prediction, and Lead Optimization: Both types of models are generally in the advanced stage across these aspects of drug discovery. In particular, In-silico Simulation and ADMET Prediction are progressing rapidly, with potential to further drive drug development.
Clinical Trials
Clinical Trial Practice and Patient Outcome Prediction: LLMs have already been applied in real-world scenarios for these tasks, indicating a matured stage of application.
Future Directions
The future application of LLMs in drug discovery and development focuses on improvements in nine key areas:
Strengthening LLM integration with biological knowledge, such as molecular generation, clinical trial data, and accurate understanding and manipulation of scientific terminology.
Addressing ethical, privacy, and misuse concerns, ensuring data security, and preventing potential abuse of the models.
Tackling fairness and bias issues to avoid unequal performance of models across different demographic groups.
Overcoming the challenge of hallucination (generating false information) in LLMs.
Enhancing multimodal processing capabilities.
Expanding the context window to handle large-scale biological data.
Improving the understanding of spatiotemporal data, especially in fields like molecular dynamics simulation.
Finally, integrating the capabilities of Specialized LMs and General LMs to achieve more accurate handling of scientific tasks, while also enabling broad user interactions to drive the automation and efficiency of drug development.
References
Zheng Y., Koh H.Y., Yang M., Li L., May L.T., Webb G.I., Pan S., and Church G., 2024. Large Language Models in Drug Discovery and Development: From Disease Mechanisms to Clinical Trials. arXiv preprint arXiv:2409.04481.





Post comments