
by Kaunas University of Technology
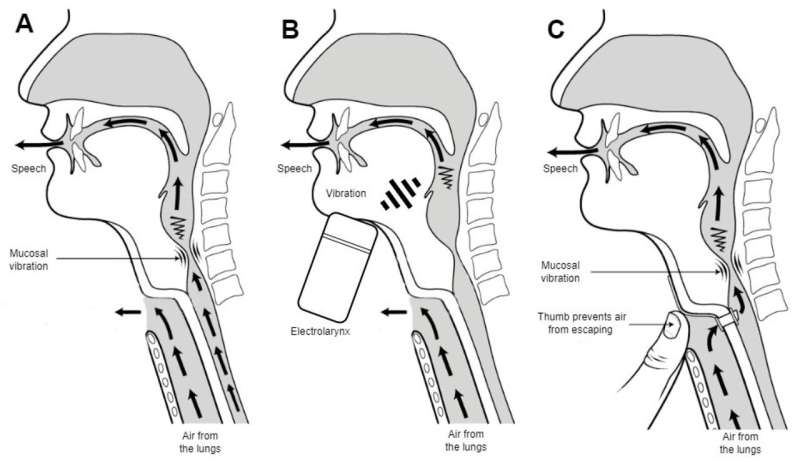
Types of speech production after total laryngectomy. (A) Esophageal speech: air is pulled in and released from the esophagus; (B) vibrations created by an electrolarynx; (C) the patient is occluding a tracheostoma to allow air to pass through the mouth. Adapted from Hurren 2015 [9]. Credit: Cancers (2023). DOI: 10.3390/cancers15143644
The most common type of laryngectomy, i.e., surgical removal of advanced laryngeal cancer, changes the patient's voice dramatically and can be very disruptive to their normal life. To improve the quality of life of patients after laryngectomy, a team of researchers from Lithuania conducted a study using artificial intelligence (AI) to "clean" the speech of laryngectomy patients.
According to the researchers—Prof Rytis Maskeliūnas from Kaunas University of Technology and Prof Virgilijus Ulozas from Lithuanian University of Health Sciences (LSMU)—laryngeal cancer patients have to undergo extended surgery to partially or completely remove their larynx. After such an operation, the patient's vocal apparatus remains damaged. Voice function is severely impaired or absent, while breathing takes place through a tracheal opening in the neck, called a tracheostomy.
In such patients, the voice produced by using the remaining anatomical structures that are not naturally designed to generate voice is called a substitute voice.
Published in the journal Cancers, the Lithuanian researchers' study addresses the disability of patients who suffered extended laryngeal cancer removal surgery. The main goal of the research is to develop artificial intelligence-based algorithms for the automatic improvement and assessment of substitute voice in patients after laryngeal cancer surgery.
The developed algorithms are being clinically tested at the largest Lithuanian university hospital—Lithuanian University of Health Sciences Hospital, at the Ear, Nose and Throat Clinic.
The IoT system that 'cleans' the language
According to Rytis Maskeliūnas, a researcher at KTU, the change in voice after laryngectomy depends on the severity of the situation—some people have a slight change in their voice, others speak like robots, and others wheeze. Therefore, it is not always easy to understand what the patient wants to say.
"By using Pareto optimization in deep learning and integrating certain techniques, we can control factors such as noise reduction, speech quality and computational efficiency. This synergy improves the efficiency of noise reduction in disrupted speech," says Maskeliūnas.
According to him, the algorithm's speech operation involves calculating the spectrogram of the noisy voice, deriving frequency statistics, measuring noise sensitivity, noise generation and other parameters that are involved in the "cleaning" of the voice.
"It is important to note that we have chosen a very topical and specialized area, based on the insights of the LSMU experts. The results of the study already show the potential to improve the intelligibility and quality of speech in the presence of a variety of factors, and we believe that we will apply this system to medical disorders and patients with different conditions," says the KTU researcher.
In the future, it is hoped that a smartphone will be able to record what the patient wants to say and then "clean up" and enrich this signal to produce a coherent and clear result.
The smartphone will help patients speak clearly
According to LSMU professor Ulozas, the research is in its experimental phase and the studies are being conducted on voice recordings from patients with ear, nose and throat diseases.
"The study involves patients at the Clinic who have undergone surgery for laryngeal cancer. These patients are left without a voice after a complete laryngeal removal operation, and then, during the next operation, a tracheoesophageal prosthesis is inserted, which allows the patients to speak, while breathing takes place through the tracheal opening," says the professor.
After such an operation, the patient regains the ability to speak, but the quality of speech is very poor, there is a lot of noise, pauses and interruptions, so it is difficult to understand what is being said, which hinders the patient's quality of life, according to Ulozas.
According to Maskeliūnas, the study aims to ensure that the speech delay is minimal, "For example, it would correspond to a comfortable telephone conversation when the surgeon calls the interlocutor. Nowadays, the telephone often 'understands' the interlocutor's voice as a noise, and the other side does not understand what is being said."
According to the researchers, once the technology has been tested to the point where it is easy to operate, the study will be carried out by meeting the patients live.
More information: Rytis Maskeliūnas et al, Pareto-Optimized Non-Negative Matrix Factorization Approach to the Cleaning of Alaryngeal Speech Signals, Cancers (2023). DOI: 10.3390/cancers15143644
Journal information: Cancers
Provided by Kaunas University of Technology




Post comments