
by Linda B. Glaser, Cornell University
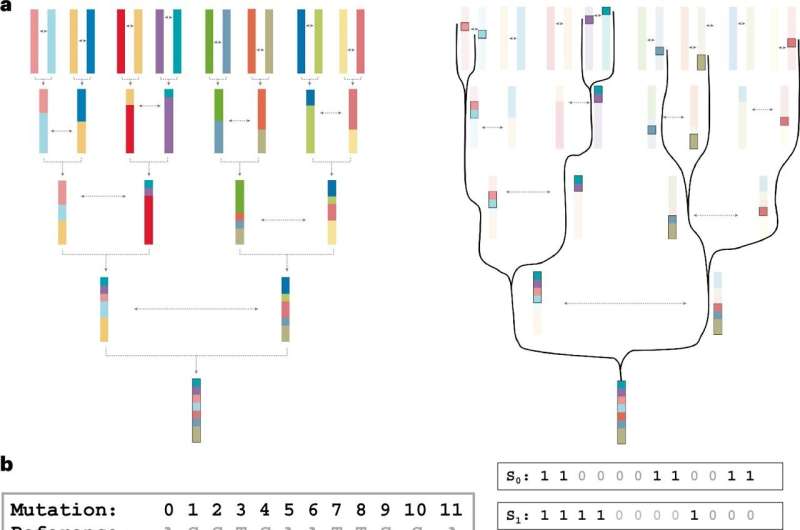
The biological interpretation of the GRG data structure. Credit: Nature Computational Science (2024). DOI: 10.1038/s43588-024-00739-9
Genomic researchers used to be able to store their datasets on a laptop, but with so many whole genomes available now to study, the resulting big datasets must be stored in the cloud—resulting in more expensive, slower and more unwieldy computations.
A new method developed at Cornell provides tools and methodologies to compress hundreds of terabytes of genomic data to gigabytes, once again enabling researchers to store datasets in local computers. Their paper, "Enabling Efficient Analysis of Biobank-Scale Data with Genotype Representation Graphs," published Dec. 5 in Nature Computational Science.
"Even just a few years ago, the data we were studying usually wasn't whole genome sequencing data, which meant only a small fraction of the genomes were being measured, rather than the entire genome. And because of that, the size of the data wasn't so crazy," said April Wei, assistant professor of computational biology in the College of Arts and Sciences.
Raw data size can now run into the petabytes, said co-author Drew DeHaas, computational genetics programmer in the College of Agriculture and Life Sciences.
Wei had always wanted to develop methods to utilize biobank-scale data for doing research because of the richness of the information available, but many of the things she wanted to do weren't possible because of the computational cost and challenge. This inspired her, she said, to tackle the compression problem, which led to the Genotype Representation Graph (GRG) method, which uses graphs to manage the data.
"Graph-based methods have long been used in computer science and other fields to provide a clear framework for solving challenging problems," DeHaas said, but prior to GRG had not been applied to a data compression solution in genomics at the Biobank scale.
Wei, trained as a population geneticist, had deep familiarity with graphs used in population genetics—although GRG is designed quite differently.
"Unlike conventional matrix-based representations, GRG represents genotypes as a graph, where relationships between individuals are captured through shared mutations in their genomes. The GRG data structure not only encodes genotypic information more intuitively and compactly, but also facilitates efficient graph-based computations for advanced analyses," said co-author Ziqing Pan, doctoral student in the field of computational biology.
GRG compresses the data while focusing on scalability and faithfully representing the data, according to Wei.
"The great benefit of utilizing graphs for compression is that we can do computations with graphs, without the need to decompress the data," she said. "Also, specific algorithms could be developed to do things that people couldn't do with older formats, so there are potentially more benefits."
Because the GRG enables researchers to analyze the same data more efficiently, it also lowers costs.
More information: Drew DeHaas et al, Enabling efficient analysis of biobank-scale data with genotype representation graphs, Nature Computational Science (2024). DOI: 10.1038/s43588-024-00739-9
Journal information: Nature Computational Science
Provided by Cornell University





Post comments